数据集载入 1 2 3 4 5 6 7 8 9 10 import pandas as pdimport numpy as npfrom matplotlib import pyplot as plt%matplotlib inline import seaborn as snsimport warningswarnings.filterwarnings('ignore' ) df = pd.read_csv("2019-08-15_泰坦尼克之灾_train.csv" ) df.head()
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
2
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
NaN
S
3
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
35.0
1
0
113803
53.1000
C123
S
4
5
0
3
Allen, Mr. William Henry
male
35.0
0
0
373450
8.0500
NaN
S
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
1 2 3 4 5 6 7 8 typedic = {} for name in df.columns: typedic[str ( df[name].dtype)] = typedic.get(str (df[name].dtype), []) + [name] for key, value in typedic.items(): print ("{}格式共有{}个: {}" .format (key, len (value), value)) print ("" )
int64格式共有5个: ['PassengerId', 'Survived', 'Pclass', 'SibSp', 'Parch']
object格式共有5个: ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']
float64格式共有2个: ['Age', 'Fare']
至此可以看到数据不全的有:[‘Age’,’Cabin’]
需要调整类型或删除无用资讯的包含:[‘Name’, ‘Sex’, ‘Ticket’, ‘Cabin’, ‘Embarked’]
1 df.Survived.value_counts()
0 549
1 342
Name: Survived, dtype: int64
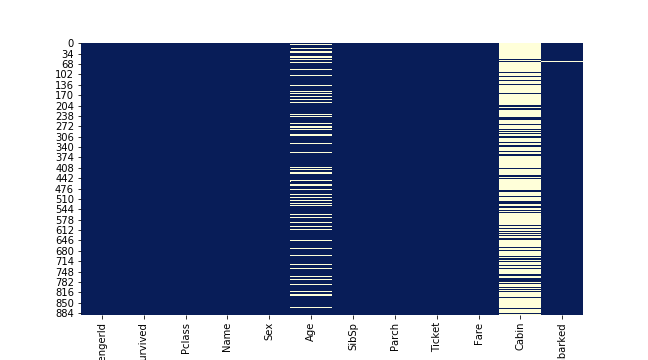
数据探索 察看空值分布 可以看到总共有三个特征有空值,分别是 Cabin 、 Age 与 Embarked
1 2 3 4 fig, ax = plt.subplots(figsize=(9 , 5 )) sns.heatmap(df.isnull(), cbar=False , cmap="YlGnBu_r" ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_1.png" ) plt.close()
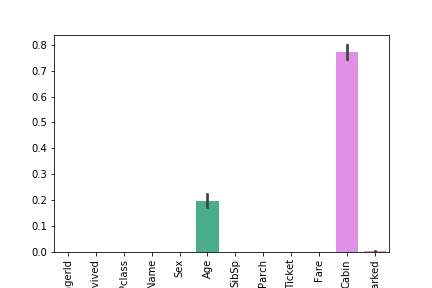
1 2 3 4 5 total = df.isnull().sum ().sort_values(ascending=False ) percent = round (df.isnull().sum ().sort_values(ascending=False ) / len (df) * 100 , 2 ) temp = pd.concat([total, percent], axis=1 , keys=['Total' , 'Percent' ]) temp
Total
Percent
Cabin
687
77.10
Age
177
19.87
Embarked
2
0.22
Fare
0
0.00
Ticket
0
0.00
Parch
0
0.00
SibSp
0
0.00
Sex
0
0.00
Name
0
0.00
Pclass
0
0.00
Survived
0
0.00
PassengerId
0
0.00
1 2 3 4 ax = sns.barplot(data=df.isnull()) plt.xticks(rotation=90 ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_2.png" ) plt.close()
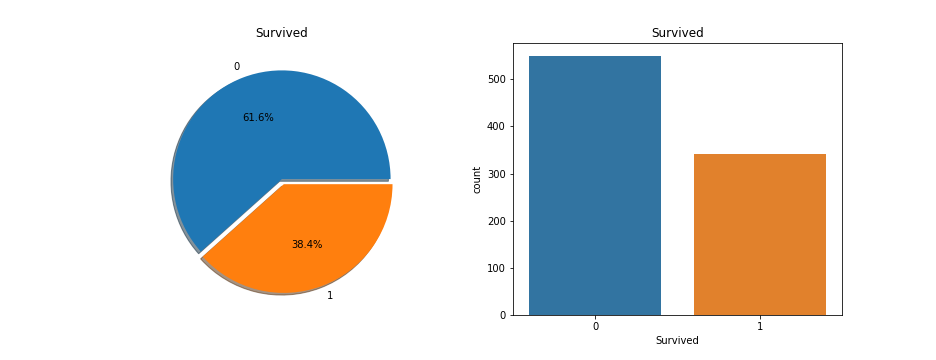
Column : Survival 存活的有 61.6%,占多数,样本比例为 1.6
1 2 3 4 5 6 7 8 9 f, ax = plt.subplots(1 , 2 , figsize=(13 , 5 )) df['Survived' ].value_counts().plot.pie( explode=[0 , 0.05 ], autopct='%1.1f%%' , ax=ax[0 ], shadow=True ) ax[0 ].set_title('Survived' ) ax[0 ].set_ylabel('' ) sns.countplot('Survived' , data=df, ax=ax[1 ]) ax[1 ].set_title('Survived' ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_3.png" ) plt.close()
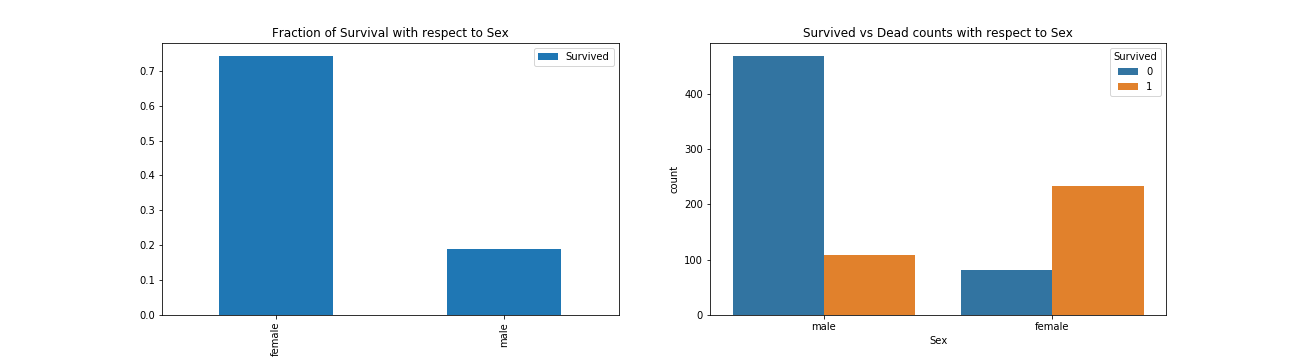
Feature: Sex 女性存活率大于7成,男性约两成
1 2 3 4 5 6 7 f, ax = plt.subplots(1 , 2 , figsize=(18 , 5 )) df[['Sex' , 'Survived' ]].groupby(['Sex' ]).mean().plot.bar(ax=ax[0 ]) ax[0 ].set_title('Fraction of Survival with respect to Sex' ) sns.countplot('Sex' , hue='Survived' , data=df, ax=ax[1 ]) ax[1 ].set_title('Survived vs Dead counts with respect to Sex' ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_4.png" ) plt.close()
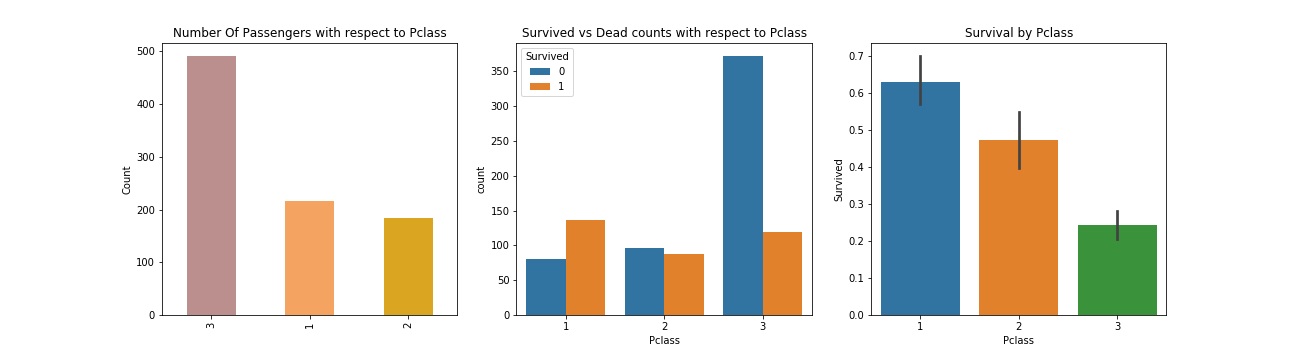
Feature: Pclass 大多数乘客在第三舱等,存活率依序从1舱等递减至3舱等
1 2 3 4 5 6 7 8 9 10 11 f, ax = plt.subplots(1 , 3 , figsize=(18 , 5 )) df['Pclass' ].value_counts().plot.bar( color=['#BC8F8F' , '#F4A460' , '#DAA520' ], ax=ax[0 ]) ax[0 ].set_title('Number Of Passengers with respect to Pclass' ) ax[0 ].set_ylabel('Count' ) sns.countplot('Pclass' , hue='Survived' , data=df, ax=ax[1 ]) ax[1 ].set_title('Survived vs Dead counts with respect to Pclass' ) sns.barplot(x="Pclass" , y="Survived" , data=df, ax=ax[2 ]) ax[2 ].set_title('Survival by Pclass' ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_5.png" ) plt.close()
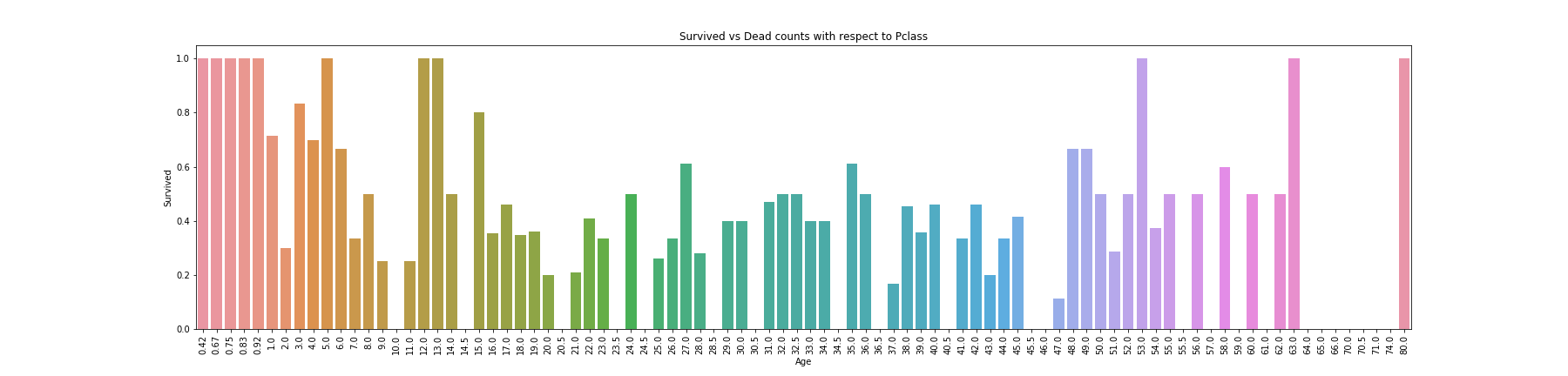
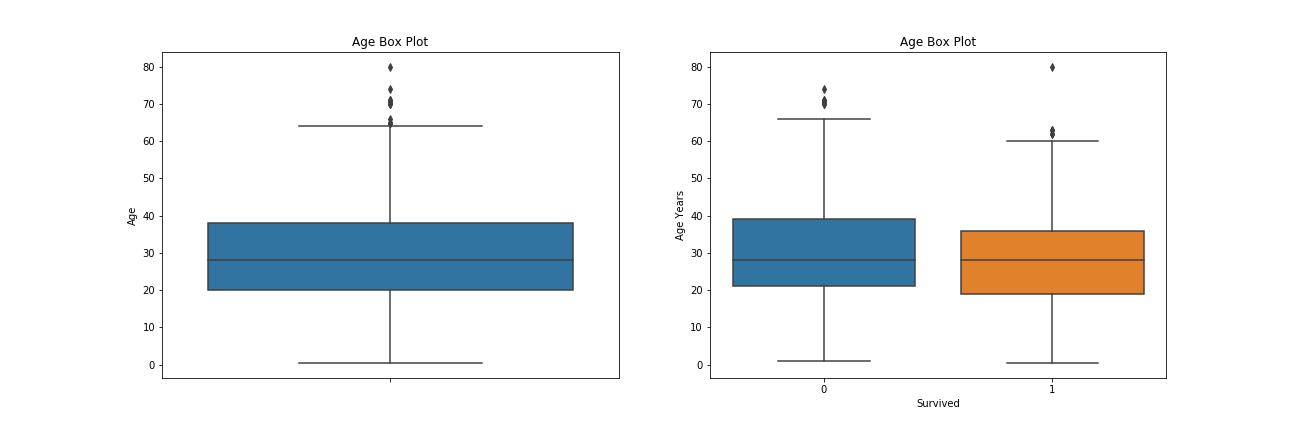
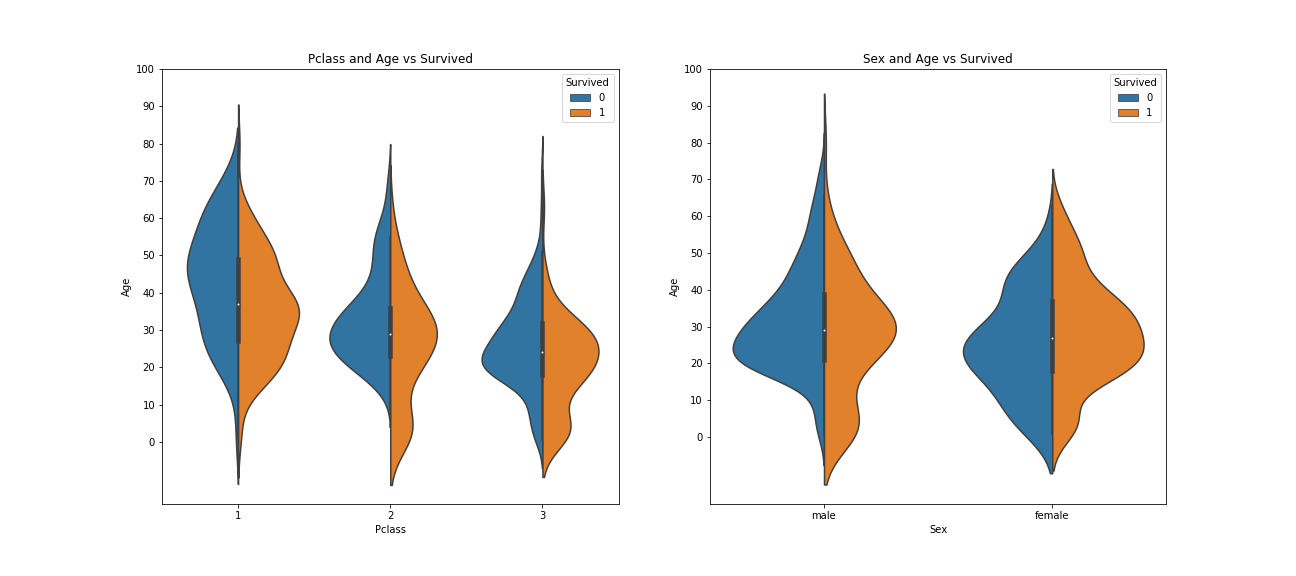
Feature: Age 年龄分布上以年轻人、小孩居多,最高有80岁老人
1 2 3 4 5 6 f, ax = plt.subplots(1 , 1 , figsize=(25 , 6 )) sns.barplot(df['Age' ], df['Survived' ], ci=None , ax=ax) ax.set_title('Survived vs Dead counts with respect to Pclass' ) plt.xticks(rotation=90 ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_6.png" ) plt.close()
1 2 3 4 5 6 7 8 9 10 11 12 13 f, ax = plt.subplots(1 , 2 , figsize=(18 , 6 )) ax[0 ].set_title('Age Box Plot' ) ax[0 ].set_ylabel('Age Years' ) sns.boxplot(y='Age' , data=df, ax=ax[0 ]) sns.boxplot(x='Survived' , y='Age' , data=df, ax=ax[1 ]) ax[1 ].set_title('Age Box Plot' ) ax[1 ].set_ylabel('Age Years' ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_7.png" ) plt.close()
1 2 3 4 5 6 7 8 9 10 11 12 f, ax = plt.subplots(1 , 2 , figsize=(18 , 8 )) sns.violinplot( "Pclass" , "Age" , hue="Survived" , data=df, split=True , ax=ax[0 ]) ax[0 ].set_title('Pclass and Age vs Survived' ) ax[0 ].set_yticks(range (0 , 110 , 10 )) sns.violinplot( "Sex" , "Age" , hue="Survived" , data=df, split=True , ax=ax[1 ]) ax[1 ].set_title('Sex and Age vs Survived' ) ax[1 ].set_yticks(range (0 , 110 , 10 )) plt.savefig("../img/2019-08-15_泰坦尼克之灾_8.png" ) plt.close()
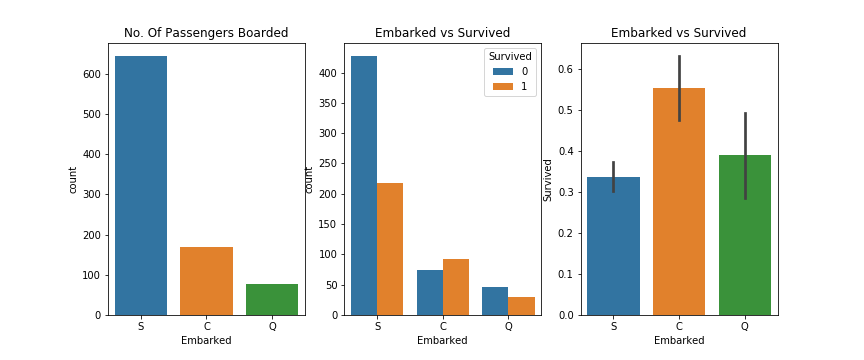
Feature: Embarked 大多数乘客是从S登船口,存活率以c最高
1 2 3 4 5 6 7 8 9 10 f, ax = plt.subplots(1 , 3 , figsize=(12 , 5 )) sns.countplot('Embarked' , data=df, ax=ax[0 ]) ax[0 ].set_title('No. Of Passengers Boarded' ) sns.countplot('Embarked' , hue='Survived' , data=df, ax=ax[1 ]) ax[1 ].set_title('Embarked vs Survived' ) sns.barplot('Embarked' , 'Survived' , data=df, ax=ax[2 ]) ax[2 ].set_title('Embarked vs Survived' ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_9.png" ) plt.close()
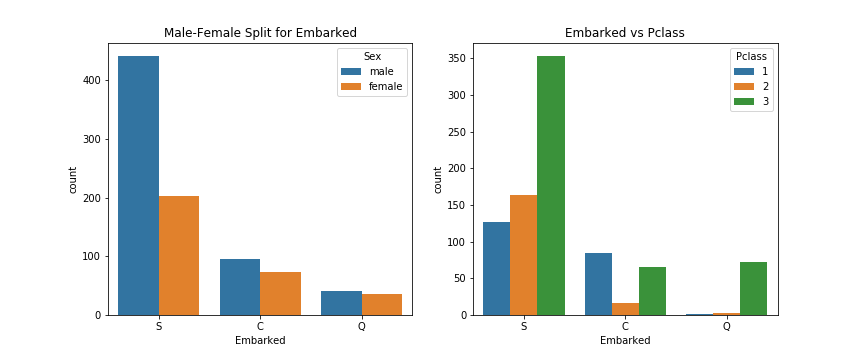
1 2 3 4 5 6 7 8 9 f, ax = plt.subplots(1 , 2 , figsize=(12 , 5 )) sns.countplot('Embarked' , hue='Sex' , data=df, ax=ax[0 ]) ax[0 ].set_title('Male-Female Split for Embarked' ) sns.countplot('Embarked' , hue='Pclass' , data=df, ax=ax[1 ]) ax[1 ].set_title('Embarked vs Pclass' ) plt.subplots_adjust(wspace=0.2 , hspace=0.5 ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_10.png" ) plt.close()
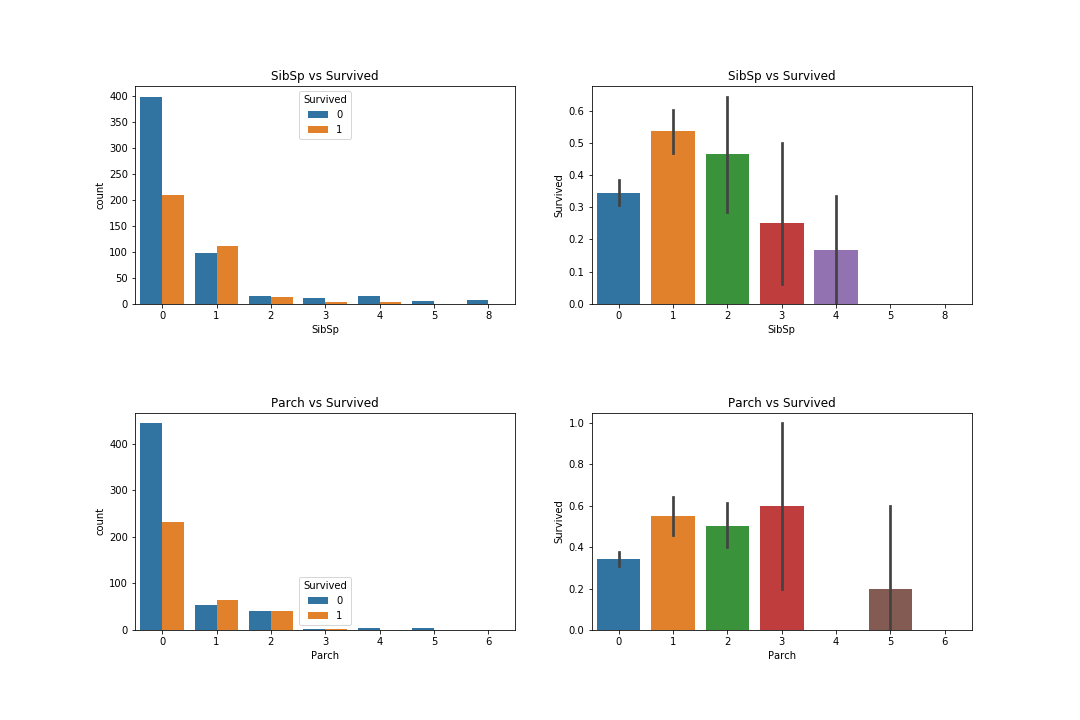
Features: SibSip & Parch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 f, ax = plt.subplots(2 , 2 , figsize=(15 , 10 )) sns.countplot('SibSp' , hue='Survived' , data=df, ax=ax[0 , 0 ]) ax[0 , 0 ].set_title('SibSp vs Survived' ) sns.barplot('SibSp' , 'Survived' , data=df, ax=ax[0 , 1 ]) ax[0 , 1 ].set_title('SibSp vs Survived' ) sns.countplot('Parch' , hue='Survived' , data=df, ax=ax[1 , 0 ]) ax[1 , 0 ].set_title('Parch vs Survived' ) sns.barplot('Parch' , 'Survived' , data=df, ax=ax[1 , 1 ]) ax[1 , 1 ].set_title('Parch vs Survived' ) plt.subplots_adjust(wspace=0.2 , hspace=0.5 ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_11.png" ) plt.close()
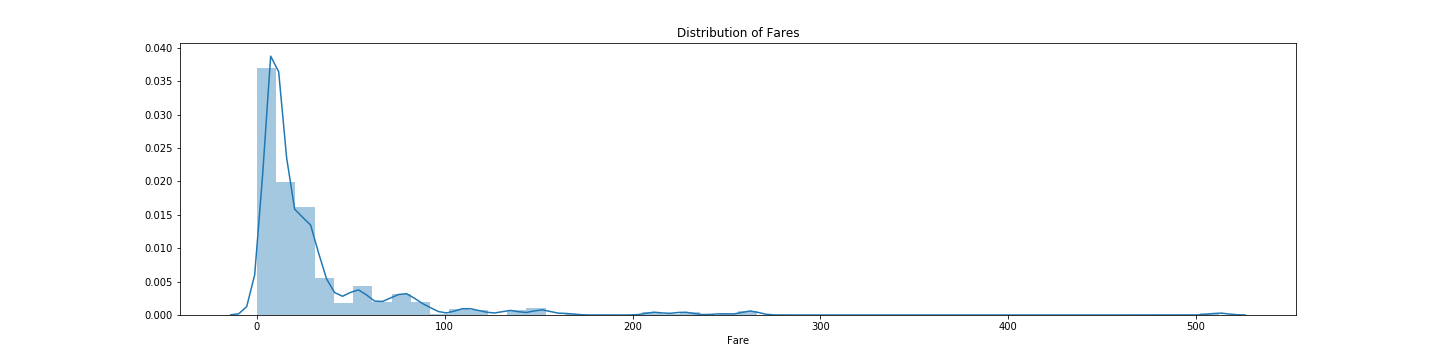
Feature: Fare 1 2 3 4 5 6 f, ax = plt.subplots(1 , 1 , figsize=(20 , 5 )) sns.distplot(df.Fare, ax=ax) ax.set_title('Distribution of Fares' ) plt.savefig("../img/2019-08-15_泰坦尼克之灾_12.png" ) plt.close()
特征预处理 1 2 df_tuned = df.copy(deep=True ) df_tuned.sample(5 )
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
390
391
1
1
Carter, Mr. William Ernest
male
36.0
1
2
113760
120.0000
B96 B98
S
281
282
0
3
Olsson, Mr. Nils Johan Goransson
male
28.0
0
0
347464
7.8542
NaN
S
691
692
1
3
Karun, Miss. Manca
female
4.0
0
1
349256
13.4167
NaN
C
866
867
1
2
Duran y More, Miss. Asuncion
female
27.0
1
0
SC/PARIS 2149
13.8583
NaN
C
726
727
1
2
Renouf, Mrs. Peter Henry (Lillian Jefferys)
female
30.0
3
0
31027
21.0000
NaN
S
删除无用特征 PassengerId 1 df_tuned = df_tuned.drop(['PassengerId' ], axis=1 )
填充空值 Age 1 2 3 4 5 6 print ("原缺失值:{a}" .format (a=df_tuned['Age' ].isnull().sum ()))df_tuned['Age' ].fillna(df_tuned['Age' ].mode()[0 ], inplace=True ) print ("后缺失值:{a}" .format (a=df_tuned['Age' ].isnull().sum ()))
原缺失值:177
后缺失值:0
Cabin 1 2 3 4 5 6 7 8 print ("原缺失值:{a}" .format (a=df_tuned['Cabin' ].isnull().sum ()))df_tuned['Cabin' ][df_tuned['Cabin' ].isnull()] = 0 df_tuned['Cabin' ][df_tuned['Cabin' ].notnull()] = 1 df_tuned['Cabin' ] = df_tuned['Cabin' ].astype(int ) print ("后缺失值:{a}" .format (a=df_tuned['Cabin' ].isnull().sum ()))
原缺失值:687
后缺失值:0
Embarked 1 2 3 4 5 6 print ("原缺失值:{a}" .format (a=df_tuned['Embarked' ].isnull().sum ()))df_tuned['Embarked' ].fillna(df_tuned['Embarked' ].mode()[0 ], inplace=True ) print ("后缺失值:{a}" .format (a=df_tuned['Embarked' ].isnull().sum ()))
原缺失值:2
后缺失值:0
特征分箱 Name:取出称号 1 df_tuned['Title' ] = df_tuned['Name' ].str .extract(',\s(.*?)\.' )
1 2 3 4 5 6 7 8 9 title_Dict = {} title_Dict.update(dict .fromkeys(['Capt' , 'Col' , 'Major' , 'Dr' , 'Rev' ], 'Officer' )) title_Dict.update(dict .fromkeys(['Jonkheer' , 'Don' , 'Sir' , 'the Countess' , 'Dona' , 'Lady' ], 'Royalty' )) title_Dict.update(dict .fromkeys(['Mme' , 'Ms' , 'Mrs' ], 'Mrs' )) title_Dict.update(dict .fromkeys(['Mlle' , 'Miss' ], 'Miss' )) title_Dict.update(dict .fromkeys(['Mr' ], 'Mr' )) title_Dict.update(dict .fromkeys(['Master' ], 'Master' )) title_Dict
{'Capt': 'Officer',
'Col': 'Officer',
'Major': 'Officer',
'Dr': 'Officer',
'Rev': 'Officer',
'Jonkheer': 'Royalty',
'Don': 'Royalty',
'Sir': 'Royalty',
'the Countess': 'Royalty',
'Dona': 'Royalty',
'Lady': 'Royalty',
'Mme': 'Mrs',
'Ms': 'Mrs',
'Mrs': 'Mrs',
'Mlle': 'Miss',
'Miss': 'Miss',
'Mr': 'Mr',
'Master': 'Master'}
1 2 3 df_tuned['Title' ] = df_tuned['Title' ].map (title_Dict) df_tuned = df_tuned.drop(['Name' ], axis=1 ) df_tuned.head()
Survived
Pclass
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
Title
0
0
3
male
22.0
1
0
A/5 21171
7.2500
1
S
Mr
1
1
1
female
38.0
1
0
PC 17599
71.2833
1
C
Mrs
2
1
3
female
26.0
0
0
STON/O2. 3101282
7.9250
1
S
Miss
3
1
1
female
35.0
1
0
113803
53.1000
1
S
Mrs
4
0
3
male
35.0
0
0
373450
8.0500
1
S
Mr
Fare 1 2 3 4 5 6 7 8 9 10 11 12 13 def fare_category (fare ): if fare <= 4 : return 0 elif fare <= 10 : return 1 elif fare <= 30 : return 2 elif fare <= 45 : return 3 else : return 4 df_tuned['Fare' ] = df_tuned['Fare' ].map (fare_category)
Family_size 1 2 3 4 5 6 7 8 9 10 11 12 13 df_tuned['Family_Size' ] = df_tuned['Parch' ] + df_tuned['SibSp' ] + 1 def family_size_category (ppl ): if ppl <= 2 : return 0 elif ppl <= 4 : return 1 elif ppl <= 6 : return 2 else : return 3 df_tuned['Family_Size' ] = df_tuned['Family_Size' ].map (family_size_category)
Ticket 1 2 3 df_tuned['Ticket' ] = df_tuned['Ticket' ].str .extract('(^\d+|\s\d+)' ) df_tuned['Ticket' ].fillna(0 ,inplace=True ) df_tuned['Ticket' ] = df_tuned['Ticket' ].astype(float )
处理分类特征
Survived
Pclass
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
Title
Family_Size
0
0
3
male
22.0
1
0
21171.0
1
1
S
Mr
0
1
1
1
female
38.0
1
0
17599.0
4
1
C
Mrs
0
2
1
3
female
26.0
0
0
3101282.0
1
1
S
Miss
0
3
1
1
female
35.0
1
0
113803.0
4
1
S
Mrs
0
4
0
3
male
35.0
0
0
373450.0
1
1
S
Mr
0
5
0
3
male
24.0
0
0
330877.0
1
1
Q
Mr
0
6
0
1
male
54.0
0
0
17463.0
4
1
S
Mr
0
7
0
3
male
2.0
3
1
349909.0
2
1
S
Master
2
8
1
3
female
27.0
0
2
347742.0
2
1
S
Mrs
1
9
1
2
female
14.0
1
0
237736.0
3
1
C
Mrs
0
10
1
3
female
4.0
1
1
9549.0
2
1
S
Miss
1
11
1
1
female
58.0
0
0
113783.0
2
1
S
Miss
0
12
0
3
male
20.0
0
0
2151.0
1
1
S
Mr
0
13
0
3
male
39.0
1
5
347082.0
3
1
S
Mr
3
14
0
3
female
14.0
0
0
350406.0
1
1
S
Miss
0
15
1
2
female
55.0
0
0
248706.0
2
1
S
Mrs
0
16
0
3
male
2.0
4
1
382652.0
2
1
Q
Master
2
17
1
2
male
24.0
0
0
244373.0
2
1
S
Mr
0
18
0
3
female
31.0
1
0
345763.0
2
1
S
Mrs
0
19
1
3
female
24.0
0
0
2649.0
1
1
C
Mrs
0
20
0
2
male
35.0
0
0
239865.0
2
1
S
Mr
0
21
1
2
male
34.0
0
0
248698.0
2
1
S
Mr
0
22
1
3
female
15.0
0
0
330923.0
1
1
Q
Miss
0
23
1
1
male
28.0
0
0
113788.0
3
1
S
Mr
0
24
0
3
female
8.0
3
1
349909.0
2
1
S
Miss
2
25
1
3
female
38.0
1
5
347077.0
3
1
S
Mrs
3
26
0
3
male
24.0
0
0
2631.0
1
1
C
Mr
0
27
0
1
male
19.0
3
2
19950.0
4
1
S
Mr
2
28
1
3
female
24.0
0
0
330959.0
1
1
Q
Miss
0
29
0
3
male
24.0
0
0
349216.0
1
1
S
Mr
0
...
...
...
...
...
...
...
...
...
...
...
...
...
861
0
2
male
21.0
1
0
28134.0
2
1
S
Mr
0
862
1
1
female
48.0
0
0
17466.0
2
1
S
Mrs
0
863
0
3
female
24.0
8
2
2343.0
4
1
S
Miss
3
864
0
2
male
24.0
0
0
233866.0
2
1
S
Mr
0
865
1
2
female
42.0
0
0
236852.0
2
1
S
Mrs
0
866
1
2
female
27.0
1
0
2149.0
2
1
C
Miss
0
867
0
1
male
31.0
0
0
17590.0
4
1
S
Mr
0
868
0
3
male
24.0
0
0
345777.0
1
1
S
Mr
0
869
1
3
male
4.0
1
1
347742.0
2
1
S
Master
1
870
0
3
male
26.0
0
0
349248.0
1
1
S
Mr
0
871
1
1
female
47.0
1
1
11751.0
4
1
S
Mrs
1
872
0
1
male
33.0
0
0
695.0
1
1
S
Mr
0
873
0
3
male
47.0
0
0
345765.0
1
1
S
Mr
0
874
1
2
female
28.0
1
0
3381.0
2
1
C
Mrs
0
875
1
3
female
15.0
0
0
2667.0
1
1
C
Miss
0
876
0
3
male
20.0
0
0
7534.0
1
1
S
Mr
0
877
0
3
male
19.0
0
0
349212.0
1
1
S
Mr
0
878
0
3
male
24.0
0
0
349217.0
1
1
S
Mr
0
879
1
1
female
56.0
0
1
11767.0
4
1
C
Mrs
0
880
1
2
female
25.0
0
1
230433.0
2
1
S
Mrs
0
881
0
3
male
33.0
0
0
349257.0
1
1
S
Mr
0
882
0
3
female
22.0
0
0
7552.0
2
1
S
Miss
0
883
0
2
male
28.0
0
0
34068.0
2
1
S
Mr
0
884
0
3
male
25.0
0
0
392076.0
1
1
S
Mr
0
885
0
3
female
39.0
0
5
382652.0
2
1
Q
Mrs
2
886
0
2
male
27.0
0
0
211536.0
2
1
S
Officer
0
887
1
1
female
19.0
0
0
112053.0
2
1
S
Miss
0
888
0
3
female
24.0
1
2
6607.0
2
1
S
Miss
1
889
1
1
male
26.0
0
0
111369.0
2
1
C
Mr
0
890
0
3
male
32.0
0
0
370376.0
1
1
Q
Mr
0
891 rows × 12 columns
Embarked, Sex, Pclass, Title, Fare_Category, Family_Size, 1 2 3 4 5 6 7 8 9 10 11 12 13 dummies_Pclass = pd.get_dummies(df_tuned['Pclass' ], prefix='Pclass' ) dummies_Sex = pd.get_dummies(df_tuned['Sex' ], prefix='Sex' ) dummies_Fare = pd.get_dummies(df_tuned['Fare' ], prefix='Pclass' ) dummies_Embarked = pd.get_dummies(df_tuned['Embarked' ], prefix='Embarked' ) dummies_Title = pd.get_dummies(df_tuned['Title' ], prefix='Pclass' ) dummies_Family_Size = pd.get_dummies(df_tuned['Family_Size' ], prefix='Pclass' ) df_tuned = pd.concat( [df_tuned, dummies_Embarked, dummies_Sex, dummies_Pclass, dummies_Title, dummies_Fare, dummies_Family_Size], axis=1 ) df_tuned.drop(['Pclass' , 'Sex' , 'Fare' , 'Embarked' , 'Title' , 'Family_Size' ], axis=1 , inplace=True )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 29 columns):
Survived 891 non-null int64
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null float64
Cabin 891 non-null int64
Embarked_C 891 non-null uint8
Embarked_Q 891 non-null uint8
Embarked_S 891 non-null uint8
Sex_female 891 non-null uint8
Sex_male 891 non-null uint8
Pclass_1 891 non-null uint8
Pclass_2 891 non-null uint8
Pclass_3 891 non-null uint8
Pclass_Master 891 non-null uint8
Pclass_Miss 891 non-null uint8
Pclass_Mr 891 non-null uint8
Pclass_Mrs 891 non-null uint8
Pclass_Officer 891 non-null uint8
Pclass_Royalty 891 non-null uint8
Pclass_0 891 non-null uint8
Pclass_1 891 non-null uint8
Pclass_2 891 non-null uint8
Pclass_3 891 non-null uint8
Pclass_4 891 non-null uint8
Pclass_0 891 non-null uint8
Pclass_1 891 non-null uint8
Pclass_2 891 non-null uint8
Pclass_3 891 non-null uint8
dtypes: float64(2), int64(4), uint8(23)
memory usage: 61.9 KB
数据标准化 1 2 3 4 from sklearn.preprocessing import StandardScalerss = StandardScaler() data = ss.fit_transform(df_tuned['Ticket' ].values.reshape(-1 , 1 )) df_tuned['Ticket' ] = pd.DataFrame(data)
数据划分 1 2 3 4 5 6 7 from sklearn.model_selection import train_test_splitX = df_tuned[:].drop("Survived" , axis=1 ) y = df_tuned["Survived" ] X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2 , shuffle=False )
数据建模 六大模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from sklearn import ensemblefrom sklearn.metrics import *from sklearn.linear_model import LogisticRegressionfrom sklearn.svm import SVCfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import cross_val_scorenames = ["LR" , "SVC" , 'DT' , "RF" , "KNN" , "GBDT" , "Voting" ] models = [LR, svc, DT, RF, KNN, GBDT, voting] evaluates = ['accuracy' , 'precision' , 'recall' , 'f1' , 'roc_auc' ] LR = LogisticRegression(C=1.0 , penalty='l1' , tol=1e-6 ) LR = LR.fit(X_train, y_train) svc = SVC(kernel='linear' , probability=True ) svc = svc.fit(X_train, y_train) DT = DecisionTreeClassifier( max_features='sqrt' , max_depth=35 , criterion='entropy' , random_state=42 ) DT = DT.fit(X_train, y_train) RF = RandomForestClassifier( n_estimators=750 , criterion='gini' , max_features='sqrt' , max_depth=3 , min_samples_split=4 , min_samples_leaf=2 , n_jobs=50 , random_state=42 , verbose=1 ) RF = RF.fit(X_train, y_train) KNN = KNeighborsClassifier() KNN = KNN.fit(X_train, y_train) GBDT = GradientBoostingClassifier( n_estimators=900 , learning_rate=0.0008 , loss='exponential' , min_samples_split=3 , min_samples_leaf=2 , max_features='sqrt' , max_depth=3 , random_state=42 , verbose=1 ) GBDT = GBDT.fit(X_train, y_train) voting = ensemble.VotingClassifier( estimators=[('LR' , LR), ('SVC' , svc), ('DT' , DT), ('RF' , RF), ('KNN' , KNN), ('GBDT' , GBDT)], voting='soft' , weights=[i.score(X_test, y_test) for i in models[0 :6 ]], n_jobs=50 ) voting = voting.fit(X_train, y_train)
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.3s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.5s finished
Iter Train Loss Remaining Time
1 0.9754 1.41s
2 0.9751 1.32s
3 0.9748 1.24s
4 0.9745 1.20s
5 0.9742 1.18s
6 0.9739 1.13s
7 0.9738 1.08s
8 0.9735 1.05s
9 0.9733 1.02s
10 0.9730 1.00s
20 0.9703 0.77s
30 0.9680 0.68s
40 0.9655 0.63s
50 0.9628 0.62s
60 0.9602 0.59s
70 0.9576 0.57s
80 0.9549 0.55s
90 0.9522 0.53s
100 0.9498 0.52s
200 0.9259 0.43s
300 0.9040 0.37s
400 0.8842 0.31s
500 0.8660 0.26s
600 0.8493 0.20s
700 0.8340 0.13s
800 0.8204 0.06s
900 0.8078 0.00s
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 df_list = [] for name,model in zip (names,models): y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_accuracy = model.score(X_train,y_train) test_accuracy = model.score(X_test,y_test) train_precision = precision_score(y_train,y_train_pred) test_precision = precision_score(y_test,y_test_pred) train_recall = recall_score(y_train,y_train_pred) test_recall = recall_score(y_test,y_test_pred) train_f1 = f1_score(y_train,y_train_pred) test_f1 = f1_score(y_test,y_test_pred) y_train_pred = model.predict_proba(X_train)[:,1 ] y_test_pred = model.predict_proba(X_test)[:,1 ] train_auc = roc_auc_score(y_train,y_train_pred) test_auc = roc_auc_score(y_test,y_test_pred) df = pd.DataFrame(np.array([train_accuracy,train_precision,train_recall,train_f1,train_auc,test_accuracy,test_precision,test_recall,test_f1,test_auc]).reshape(2 ,-1 ), index = ['train' ,'test' ], columns = ['Accuracy' ,'Precision' ,'Recall' ,'F1-Score' ,'AUC-Score' ]) df_list.append(df) pd.concat(df_list,axis=0 ,keys=names)
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.2s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.2s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.2s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.2s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.2s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.0s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.1s finished
Accuracy
Precision
Recall
F1-Score
AUC-Score
LR
train
0.817416
0.791339
0.723022
0.755639
0.873811
test
0.860335
0.819672
0.781250
0.800000
0.912772
SVC
train
0.820225
0.804878
0.712230
0.755725
0.860508
test
0.854749
0.816667
0.765625
0.790323
0.899321
DT
train
0.998596
1.000000
0.996403
0.998198
0.999992
test
0.754190
0.642857
0.703125
0.671642
0.748981
RF
train
0.817416
0.803279
0.705036
0.750958
0.872949
test
0.843575
0.810345
0.734375
0.770492
0.895856
KNN
train
0.841292
0.839506
0.733813
0.783109
0.918315
test
0.821229
0.758065
0.734375
0.746032
0.852921
GBDT
train
0.818820
0.898396
0.604317
0.722581
0.881597
test
0.843575
0.909091
0.625000
0.740741
0.904823
Voting
train
0.856742
0.872881
0.741007
0.801556
0.971074
test
0.860335
0.830508
0.765625
0.796748
0.898505
数据预测 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 df_test = pd.read_csv("2019-08-15_泰坦尼克之灾_test.csv" ) df_tuned_test = df_test.copy(deep=True ) df_tuned_test = df_tuned_test.drop(['PassengerId' ], axis=1 ) df_tuned_test['Age' ].fillna(df_tuned_test['Age' ].mode()[0 ], inplace=True ) df_tuned_test['Cabin' ][df_tuned_test['Cabin' ].isnull()] = 0 df_tuned_test['Cabin' ][df_tuned_test['Cabin' ].notnull()] = 1 df_tuned_test['Cabin' ] = df_tuned_test['Cabin' ].astype(int ) df_tuned_test['Embarked' ].fillna( df_tuned_test['Embarked' ].mode()[0 ], inplace=True ) df_tuned_test['Title' ] = df_tuned_test['Name' ].str .extract(',\s(.*?)\.' ) df_tuned_test['Title' ] = df_tuned_test['Title' ].map (title_Dict) df_tuned_test = df_tuned_test.drop(['Name' ], axis=1 ) df_tuned_test['Fare' ] = df_tuned_test['Fare' ].map (fare_category) df_tuned_test[ 'Family_Size' ] = df_tuned_test['Parch' ] + df_tuned_test['SibSp' ] + 1 df_tuned_test['Family_Size' ] = df_tuned_test['Family_Size' ].map ( family_size_category) df_tuned_test['Ticket' ] = df_tuned_test['Ticket' ].str .extract('(^\d+|\s\d+)' ) df_tuned_test['Ticket' ].fillna(0 , inplace=True ) df_tuned_test['Ticket' ] = df_tuned_test['Ticket' ].astype(float ) dummies_Pclass = pd.get_dummies(df_tuned_test['Pclass' ], prefix='Pclass' ) dummies_Sex = pd.get_dummies(df_tuned_test['Sex' ], prefix='Sex' ) dummies_Fare = pd.get_dummies(df_tuned_test['Fare' ], prefix='Pclass' ) dummies_Embarked = pd.get_dummies(df_tuned_test['Embarked' ], prefix='Embarked' ) dummies_Title = pd.get_dummies(df_tuned_test['Title' ], prefix='Pclass' ) dummies_Family_Size = pd.get_dummies( df_tuned_test['Family_Size' ], prefix='Pclass' ) df_tuned_test = pd.concat([ df_tuned_test, dummies_Embarked, dummies_Sex, dummies_Pclass, dummies_Title, dummies_Fare, dummies_Family_Size ], axis=1 ) df_tuned_test.drop( ['Pclass' , 'Sex' , 'Fare' , 'Embarked' , 'Title' , 'Family_Size' ], axis=1 , inplace=True ) data = ss.fit_transform(df_tuned_test['Ticket' ].values.reshape(-1 , 1 )) df_tuned_test['Ticket' ] = pd.DataFrame(data)
1 2 3 4 5 6 predictions = voting.predict(df_tuned_test) result = pd.DataFrame({ 'PassengerId' : df_test['PassengerId' ].as_matrix(), 'Survived' : predictions.astype(np.int32) }) result.to_csv("2019-08-15_泰坦尼克之灾_predictions.csv" , index=False )
[Parallel(n_jobs=50)]: Using backend ThreadingBackend with 50 concurrent workers.
[Parallel(n_jobs=50)]: Done 100 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 350 tasks | elapsed: 0.1s
[Parallel(n_jobs=50)]: Done 750 out of 750 | elapsed: 0.2s finished
参考:
集成学习voting Classifier在sklearn中的实现 Kaggle泰坦尼克号生存模型——250个特征量的融合模型,排名8% Basic Feature Visualizations