数据集载入 1 2 3 4 5 6 7 8 9 import pandas as pdimport numpy as npfrom matplotlib import pyplot as pltimport seaborn as snsimport warningswarnings.filterwarnings('ignore' ) df = pd.read_csv(u"2019-08-01_金融数据描述_data1.csv" ,encoding = 'gbk' )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4754 entries, 0 to 4753
Data columns (total 90 columns):
Unnamed: 0 4754 non-null int64
custid 4754 non-null int64
trade_no 4754 non-null object
bank_card_no 4754 non-null object
low_volume_percent 4752 non-null float64
middle_volume_percent 4752 non-null float64
take_amount_in_later_12_month_highest 4754 non-null int64
trans_amount_increase_rate_lately 4751 non-null float64
trans_activity_month 4752 non-null float64
trans_activity_day 4752 non-null float64
transd_mcc 4752 non-null float64
trans_days_interval_filter 4746 non-null float64
trans_days_interval 4752 non-null float64
regional_mobility 4752 non-null float64
student_feature 1756 non-null float64
repayment_capability 4754 non-null int64
is_high_user 4754 non-null int64
number_of_trans_from_2011 4752 non-null float64
first_transaction_time 4752 non-null float64
historical_trans_amount 4754 non-null int64
historical_trans_day 4752 non-null float64
rank_trad_1_month 4752 non-null float64
trans_amount_3_month 4754 non-null int64
avg_consume_less_12_valid_month 4752 non-null float64
abs 4754 non-null int64
top_trans_count_last_1_month 4752 non-null float64
avg_price_last_12_month 4754 non-null int64
avg_price_top_last_12_valid_month 4650 non-null float64
reg_preference_for_trad 4752 non-null object
trans_top_time_last_1_month 4746 non-null float64
trans_top_time_last_6_month 4746 non-null float64
consume_top_time_last_1_month 4746 non-null float64
consume_top_time_last_6_month 4746 non-null float64
cross_consume_count_last_1_month 4328 non-null float64
trans_fail_top_count_enum_last_1_month 4738 non-null float64
trans_fail_top_count_enum_last_6_month 4738 non-null float64
trans_fail_top_count_enum_last_12_month 4738 non-null float64
consume_mini_time_last_1_month 4728 non-null float64
max_cumulative_consume_later_1_month 4754 non-null int64
max_consume_count_later_6_month 4746 non-null float64
railway_consume_count_last_12_month 4742 non-null float64
pawns_auctions_trusts_consume_last_1_month 4754 non-null int64
pawns_auctions_trusts_consume_last_6_month 4754 non-null int64
jewelry_consume_count_last_6_month 4742 non-null float64
status 4754 non-null int64
source 4754 non-null object
first_transaction_day 4752 non-null float64
trans_day_last_12_month 4752 non-null float64
id_name 4478 non-null object
apply_score 4450 non-null float64
apply_credibility 4450 non-null float64
query_org_count 4450 non-null float64
query_finance_count 4450 non-null float64
query_cash_count 4450 non-null float64
query_sum_count 4450 non-null float64
latest_query_time 4450 non-null object
latest_one_month_apply 4450 non-null float64
latest_three_month_apply 4450 non-null float64
latest_six_month_apply 4450 non-null float64
loans_score 4457 non-null float64
loans_credibility_behavior 4457 non-null float64
loans_count 4457 non-null float64
loans_settle_count 4457 non-null float64
loans_overdue_count 4457 non-null float64
loans_org_count_behavior 4457 non-null float64
consfin_org_count_behavior 4457 non-null float64
loans_cash_count 4457 non-null float64
latest_one_month_loan 4457 non-null float64
latest_three_month_loan 4457 non-null float64
latest_six_month_loan 4457 non-null float64
history_suc_fee 4457 non-null float64
history_fail_fee 4457 non-null float64
latest_one_month_suc 4457 non-null float64
latest_one_month_fail 4457 non-null float64
loans_long_time 4457 non-null float64
loans_latest_time 4457 non-null object
loans_credit_limit 4457 non-null float64
loans_credibility_limit 4457 non-null float64
loans_org_count_current 4457 non-null float64
loans_product_count 4457 non-null float64
loans_max_limit 4457 non-null float64
loans_avg_limit 4457 non-null float64
consfin_credit_limit 4457 non-null float64
consfin_credibility 4457 non-null float64
consfin_org_count_current 4457 non-null float64
consfin_product_count 4457 non-null float64
consfin_max_limit 4457 non-null float64
consfin_avg_limit 4457 non-null float64
latest_query_day 4450 non-null float64
loans_latest_day 4457 non-null float64
dtypes: float64(70), int64(13), object(7)
memory usage: 3.3+ MB
特征预处理 删除无用 1 2 delete = ['Unnamed: 0' , 'custid' , 'trade_no' , 'bank_card_no' ,'id_name' ,'latest_query_time' ,'source' ,'loans_latest_time' ,'first_transaction_time' , 'student_feature' ] df = df.drop(delete,axis=1 )
处理分类型特征 1 2 from sklearn.preprocessing import LabelEncoderdf['reg_preference_for_trad' ] = LabelEncoder().fit_transform(df['reg_preference_for_trad' ].astype(str ))
使用众数填充 1 2 3 4 5 from sklearn.preprocessing import Imputerfor i in range (df.shape[1 ]): feature = df.iloc[:,i].values.reshape(-1 ,1 ) imp_mode = Imputer(strategy='most_frequent' ) df.iloc[:,i] = imp_mode.fit_transform(feature)
数据划分 1 2 X = df[:].drop("status" ,axis=1 ) y = df["status" ]
1 2 3 from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2 , shuffle = False )
数据归一化 1 2 3 from sklearn.preprocessing import minmax_scaleX_train = minmax_scale(X_train) X_test = minmax_scale(X_test)
建模与预测 使用一般建模方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from sklearn.metrics import *from sklearn.linear_model import LogisticRegressionfrom sklearn.svm import SVCfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import cross_val_scoreLR = LogisticRegression() LR = LR.fit(X_train, y_train) svc = SVC(kernel='linear' , probability = True ) svc = svc.fit(X_train, y_train) DT = DecisionTreeClassifier(max_depth = 6 ) DT = DT.fit(X_train, y_train) RF = RandomForestClassifier() RF = RF.fit(X_train, y_train) KNN = KNeighborsClassifier() KNN = KNN.fit(X_train, y_train) GBDT = GradientBoostingClassifier() GBDT = GBDT.fit(X_train, y_train) names = ["LR" , "SVC" , 'DT' , "RF" , "KNN" , "GBDT" ] models = [LR, svc, DT, RF, KNN, GBDT] evaluates = ['accuracy' , 'precision' , 'recall' , 'f1' , 'roc_auc' ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 df_list = [] for name,model in zip (names,models): y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_accuracy = model.score(X_train,y_train) test_accuracy = model.score(X_test,y_test) train_precision = precision_score(y_train,y_train_pred) test_precision = precision_score(y_test,y_test_pred) train_recall = recall_score(y_train,y_train_pred) test_recall = recall_score(y_test,y_test_pred) train_f1 = f1_score(y_train,y_train_pred) test_f1 = f1_score(y_test,y_test_pred) y_train_pred = model.predict_proba(X_train)[:,1 ] y_test_pred = model.predict_proba(X_test)[:,1 ] train_auc = roc_auc_score(y_train,y_train_pred) test_auc = roc_auc_score(y_test,y_test_pred) print ('{} 训练集: accuracy:{:.3},precision:{:.3}, recall:{:.3}, f1:{:.3}, auc:{:.3}' .format (name,train_accuracy,train_precision,train_recall,train_f1,train_auc)) print ('{} 测试集: accuracy:{:.3},precision:{:.3}, recall:{:.3}, f1:{:.3}, auc:{:.3}' .format (name,test_accuracy,test_precision,test_recall,test_f1,test_auc)) print ('\n' ) df = pd.DataFrame(np.array([train_accuracy,train_precision,train_recall,train_f1,train_auc,test_accuracy,test_precision,test_recall,test_f1,test_auc]).reshape(2 ,-1 ), index = ['train' ,'test' ], columns = ['Accuracy' ,'Precision' ,'Recall' ,'F1-Score' ,'AUC-Score' ]) df_list.append(df) pd.concat(df_list,axis=0 ,keys=names)
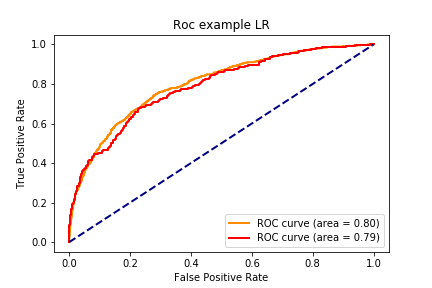
LR 训练集: accuracy:0.801,precision:0.742, recall:0.279, f1:0.406, auc:0.8
LR 测试集: accuracy:0.789,precision:0.752, recall:0.365, f1:0.491, auc:0.787
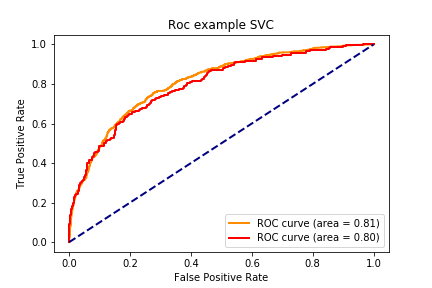
SVC 训练集: accuracy:0.793,precision:0.809, recall:0.196, f1:0.316, auc:0.809
SVC 测试集: accuracy:0.771,precision:0.843, recall:0.222, f1:0.351, auc:0.796
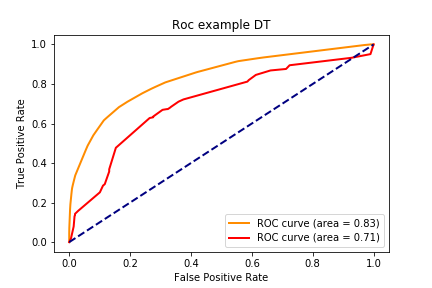
DT 训练集: accuracy:0.829,precision:0.723, recall:0.487, f1:0.582, auc:0.832
DT 测试集: accuracy:0.727,precision:0.516, recall:0.361, f1:0.425, auc:0.707
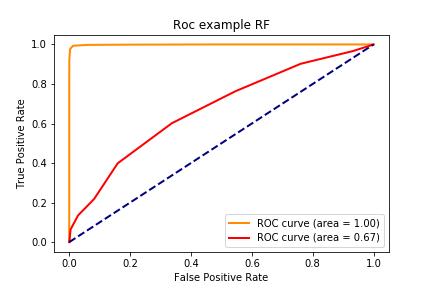
RF 训练集: accuracy:0.981,precision:0.999, recall:0.924, f1:0.96, auc:0.999
RF 测试集: accuracy:0.722,precision:0.509, recall:0.218, f1:0.305, auc:0.673
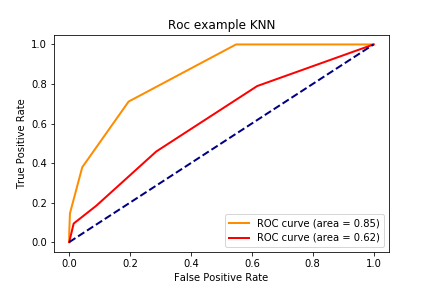
KNN 训练集: accuracy:0.816,precision:0.741, recall:0.379, f1:0.501, auc:0.848
KNN 测试集: accuracy:0.708,precision:0.445, recall:0.184, f1:0.261, auc:0.623
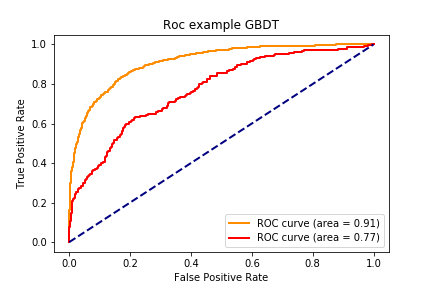
GBDT 训练集: accuracy:0.859,precision:0.867, recall:0.497, f1:0.632, auc:0.913
GBDT 测试集: accuracy:0.754,precision:0.573, recall:0.474, f1:0.519, auc:0.771
Accuracy
Precision
Recall
F1-Score
AUC-Score
LR
train
0.800684
0.742120
0.279396
0.405956
0.799942
test
0.788644
0.751938
0.364662
0.491139
0.786801
SVC
train
0.792795
0.808889
0.196332
0.315972
0.809276
test
0.770768
0.842857
0.221805
0.351190
0.796191
DT
train
0.829345
0.722756
0.486516
0.581560
0.831990
test
0.726604
0.516129
0.360902
0.424779
0.706676
RF
train
0.981331
0.998834
0.924488
0.960224
0.999103
test
0.722397
0.508772
0.218045
0.305263
0.672949
KNN
train
0.816198
0.740506
0.378641
0.501071
0.847694
test
0.707676
0.445455
0.184211
0.260638
0.623415
GBDT
train
0.858796
0.866541
0.497303
0.631940
0.912630
test
0.753943
0.572727
0.473684
0.518519
0.770979
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def draw_roc_curve (train_pre_proba,test_pre_proba,train_auc,test_auc,model_name,num ): fpr,tpr,roc_auc = train_pre_proba test_fpr,test_tpr,test_roc_auc = test_pre_proba plt.figure() lw = 2 plt.plot(fpr, tpr, color='darkorange' , lw=lw, label='ROC curve (area = %0.2f)' % train_auc) plt.plot(test_fpr, test_tpr, color='red' , lw=lw, label='ROC curve (area = %0.2f)' %test_auc) plt.plot([0 , 1 ], [0 , 1 ], color='navy' , lw=lw, linestyle='--' ) plt.xlabel('False Positive Rate' ) plt.ylabel('True Positive Rate' ) plt.title('Roc example ' + model_name) plt.legend(loc="lower right" ) plt.savefig("../img/2019-08-07_5种分类模型比较_{}.png" .format (num)) plt.close() for num,name,model in zip (range (1 ,7 ),names,models): y_train_pred = model.predict_proba(X_train)[:,1 ] y_test_pred = model.predict_proba(X_test)[:,1 ] train_roc = roc_curve(y_train,y_train_pred) test_roc = roc_curve(y_test,y_test_pred) train_auc = roc_auc_score(y_train,y_train_pred) test_auc = roc_auc_score(y_test,y_test_pred) draw_roc_curve(train_roc,test_roc,train_auc,test_auc,name,num)
使用k-folds交叉建模 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from sklearn.model_selection import KFolddef run_cv (X,y,clf_class,**kwargs ): kf = KFold(n_splits = 5 , shuffle = False , random_state = 0 ) y_pred = y.copy() clf = clf_class(**kwargs) for train_index , test_index in kf.split(X): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] clf.fit(X_train,y_train) y_pred[test_index] = clf.predict(X_test) return y_pred
1 2 3 4 5 6 7 8 9 10 from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifierfrom sklearn.svm import SVCfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.model_selection import cross_val_scorefrom sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegressionLR_CV_result = run_cv(X_train,y_train,LogisticRegression) RF_CV_result = run_cv(X_train,y_train,RandomForestClassifier) KNN_CV_result = run_cv(X_train,y_train,KNeighborsClassifier)
1 2 3 4 5 6 def accuracy (y_true,y_pred ): return np.mean(y_true == y_pred) print ("Logistic Regression (L2 is default): " + str (accuracy(y_train, LR_CV_result)))print ("Random forest: " + str (accuracy(y_train, RF_CV_result)))print ("K-nearest-neighbors: " + str (accuracy(y_train, KNN_CV_result)))
Logistic Regression (L2 is default): 0.7933210623192216
Random forest: 0.7812253484091507
K-nearest-neighbors: 0.7520378648435446
参考:
DataWhale数据挖掘实战营 吴裕雄 PYTHON 机器学习——集成学习梯度提升决策树GRADIENTBOOSTINGCLASSIFIER分类模型 使用5种分类模型进行用户贷款逾期预测 sklearn.model_selection.KFold