# -*- coding: utf-8 -*- import pandas as pd import numpy as np from matplotlib import pyplot as plt import seaborn as sns import warnings from sklearn.preprocessing import minmax_scale from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import Imputer from sklearn.model_selection import train_test_split warnings.filterwarnings('ignore')
X_trainval,y_trainval = X_train,y_train X_train,X_val,y_train,y_val = train_test_split(X_trainval,y_trainval) print("Size of training set:{} size of validation set:{} size of teseting set:{}".format(X_train.shape[0],X_val.shape[0],X_test.shape[0]))
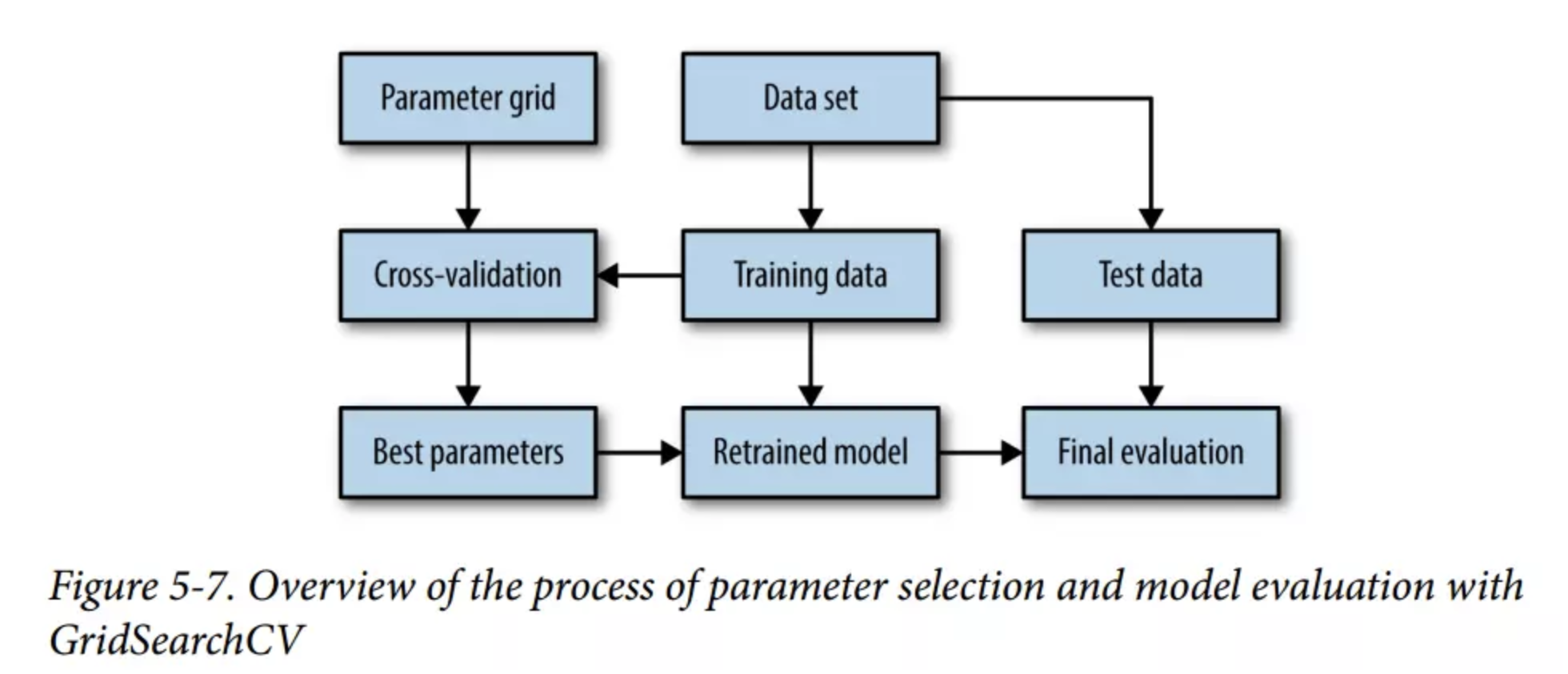
best_score = 0.0 for gamma in [0.001,0.01,0.1,1,10,100]: for C in [0.001,0.01,0.1,1,10,100]: svm = SVC(gamma=gamma,C=C) svm.fit(X_train,y_train) score = svm.score(X_val,y_val) if score > best_score: best_score = score best_parameters = {'gamma':gamma,'C':C} svm = SVC(**best_parameters) svm.fit(X_trainval,y_trainval) test_score = svm.score(X_test,y_test) print("Best score on validation set:{:.2f}".format(best_score)) print("Best parameters:{}".format(best_parameters)) print("Best score on test set:{:.2f}".format(test_score))
Size of training set:2852 size of validation set:951 size of teseting set:951
Best score on validation set:0.79
Best parameters:{'gamma': 0.01, 'C': 100}
Best score on test set:0.76
print("Test set score:{:.2f}".format(grid_search.score(X_test,y_test))) print("Best parameters:{}".format(grid_search.best_params_)) print("Best score on train set:{:.2f}".format(grid_search.best_score_))
Parameters:{'gamma': [0.001, 0.01, 0.1, 1, 10, 100], 'C': [0.001, 0.01, 0.1, 1, 10, 100]}
Test set score:0.77
Best parameters:{'C': 10, 'gamma': 0.1}
Best score on train set:0.79